Exercise 4: Explore log events interactively
Since sales are dropping and nobody knows why, you want to
provide a way for people to interactively and flexibly explore data from the
website. We can do this by indexing it for use in Apache Solr, where users can
do text searches, drill down through different categories, etc. Data can be
indexed by Solr in batch using MapReduce, or you can index tables in HBase and
get real-time updates. To analyze data from the website, however, we're going
to stream the log data in using Flume.
The web log data is a standard web server log which may
look something like this:

Solr organizes data similarly to the way a SQL database
does. Each record is called a 'document' and consists of fields defined by the
schema: just like a row in a database table. Instead of a table, Solr calls it
a 'collection' of documents. The difference is that data in Solr tends to be
more loosely structured. Fields may be optional, and instead of always matching
exact values, you can also enter text queries that partially match a field,
just like you're searching for web pages. You'll also see Hue refer to 'shards'
- and that's just the way Solr breaks collections up to spread them around the
cluster so you can search all your data in parallel.
Here is how you can start real-time-indexing via Cloudera
Search and Flume over the sample web server log data and use the Search UI in
Hue to explore it:
Create Your Search Index
Ordinarily when you are deploying a new search schema,
there are four steps:
- Creating an empty
configuration
First, generate the configs by executing the following
command:
> solrctl --zk
{{zookeeper_connection_string}}/solr instancedir --generate solr_configs
The result of this command is a skeleton configuration
that you can customize to your liking via the conf/schema.xml.
- Edit your schema
The most likely area in conf/schema.xml that you would be
interested in is the <fields></fields> section. From this area you
can define the fields that are present and searchable in your index.
- Uploading your configuration
4.
> cd
/opt/examples/flume
5.
>
solrctl --zk {{zookeeper_connection_string}}/solr instancedir --create
live_logs ./solr_configs
You may need to replace the IP addresses with those of your
three data nodes.
- Creating your collection
7.
solrctl
--zk {{zookeeper_connection_string}}/solr collection --create live_logs -s {{
number of solr servers }}
You may need to replace the IP addresses with those of your
three data nodes.
You can verify that you successfully created your
collection in Solr by going to Hue, and clicking Search in the top
menu
Then click on Indexes from the top
right to see all of the indexes/collections.

Now you can see the collection that we just created, live_logs, click on it.

You are now viewing the fields that we defined in our
schema.xml file.
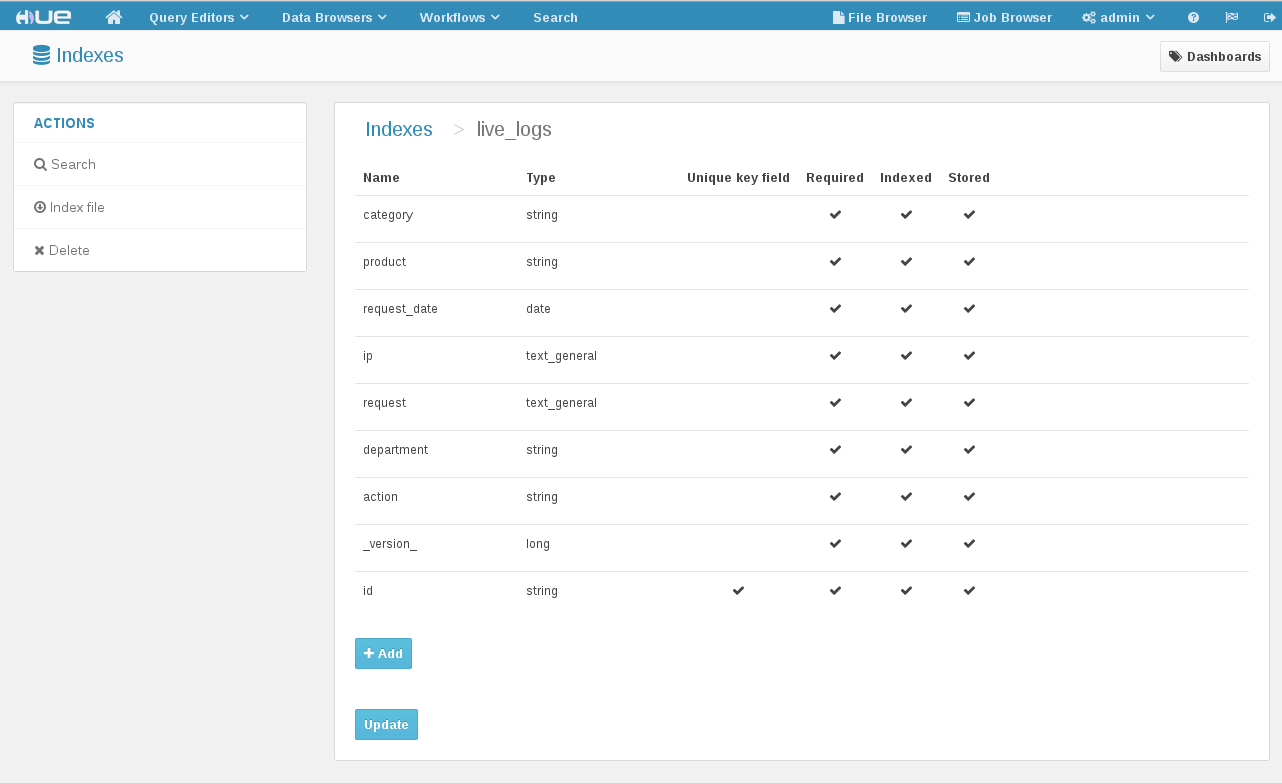
Now that you have verified that your search
collection/index was created successfully, we can start putting data into it
using Flume and Morphlines. Flume is a tool for ingesting streams of data into
your cluster from sources such as log files, network streams, and more.
Morphlines is a Java library for doing ETL on-the-fly, and it's an excellent
companion to Flume. It allows you to define a chain of tasks like reading
records, parsing and formatting individual fields, and deciding where to send
them, etc. We've defined a morphline that reads records from Flume, breaks them
into the fields we want to search on, and loads them into Solr (You can read
more about Morphlines here). This example Morphline is defined at
/opt/examples/flume/conf/morphline.conf, and we're going to use it to index our
records in real-time as they're created and ingested by Flume.
Flume and the Morphline
Now that we have an empty Solr index, and live log events
coming in to our fake access.log, we can use Flume and morphlines to load the
index with the real-time log data.
The key player in this tutorial is Flume. Flume is a system
for collecting, aggregating, and moving large amounts of log data from many
different sources to a centralized data source.
With a few simple configuration files, we can use Flume
and a morphline (a simple way to accomplish on-the-fly ETL,) to load our data
into our Solr index.
You can use Flume to load many other types of data stores;
Solr is just the example we are using for this tutorial.
Start the Flume agent by executing the following command:
> flume-ng agent \
--conf /opt/examples/flume/conf \
--conf-file /opt/examples/flume/conf/flume.conf
\
--name agent1 \
-Dflume.root.logger=DEBUG,INFO,console
This will start running the Flume agent in the foreground.
Once it has started, and is processing records, you should see something like:

Now you can go back to the Hue UI, and click 'Search' from
the collection's page:

You will be able to search, drill down into, and browse
the events that have been indexed.

If one of these steps fails, please reach out to the Discussion Forum and get help. Otherwise,
you can start exploring the log data and understand what is going on.
For our story's sake, we pretend that you started indexing
data the same time as you started ingesting it (via Flume) to the platform, so
that when your manager escalated the issue, you could immediately drill down
into data from the last three days and explore what happened. For example,
perhaps you noted a lot of DDOS events and could take the right measures to
preempt the attack. Problem solved! Management is fantastically happy with your
recent contributions, which of course leads to a great bonus or something
similar. :D
Conclusion:
Now you have learned how to use Cloudera Search to allow
exploration of data in real time, using Flume and Solr and Morphlines. Further,
you now understand how you can serve multiple use cases over the same data - as
well as from previous steps: serve multiple data sets to provide bigger
insights. The flexibility and multi-workload capability of a Hadoop-based
Enterprise Data Hub are some of the core elements that have made Hadoop
valuable to organizations world wide.
No comments:
Post a Comment